Query-Free Adversarial Transfer via Undertrained Surrogates
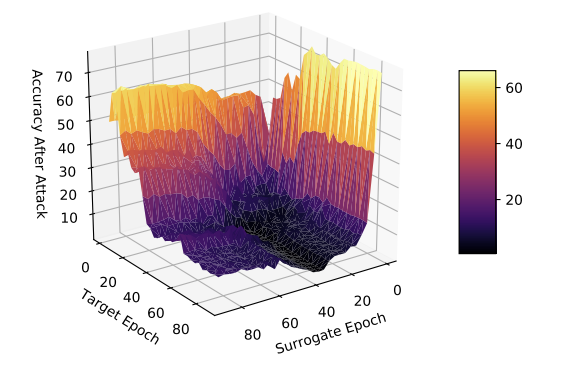 Adversarial transferability by surrogate and target model training epoch (lower values indicate greater transferability).
Adversarial transferability by surrogate and target model training epoch (lower values indicate greater transferability).Abstract
Deep neural networks are vulnerable to adversarial examples—minor perturbations added to a model’s input which cause the model to output an incorrect prediction. We introduce a new method for improving the efficacy of adversarial attacks in a black-box setting by undertraining the surrogate model which the attacks are generated on. Using two datasets and five model architectures, we show that this method transfers well across architectures and outperforms state-of-the-art methods by a wide margin. We interpret the effectiveness of our approach as a function of reduced surrogate model loss function curvature and increased universal gradient characteristics, and show that our approach reduces the presence of local loss maxima which hinder transferability. Our results suggest that finding strong single surrogate models is a highly effective and simple method for generating transferable adversarial attacks, and that this method represents a valuable route for future study.